In autonomous driving, predicting future events in advance and evaluating the foreseeable risks empowers autonomous vehicles to better plan their actions, enhancing safety and efficiency on the road.
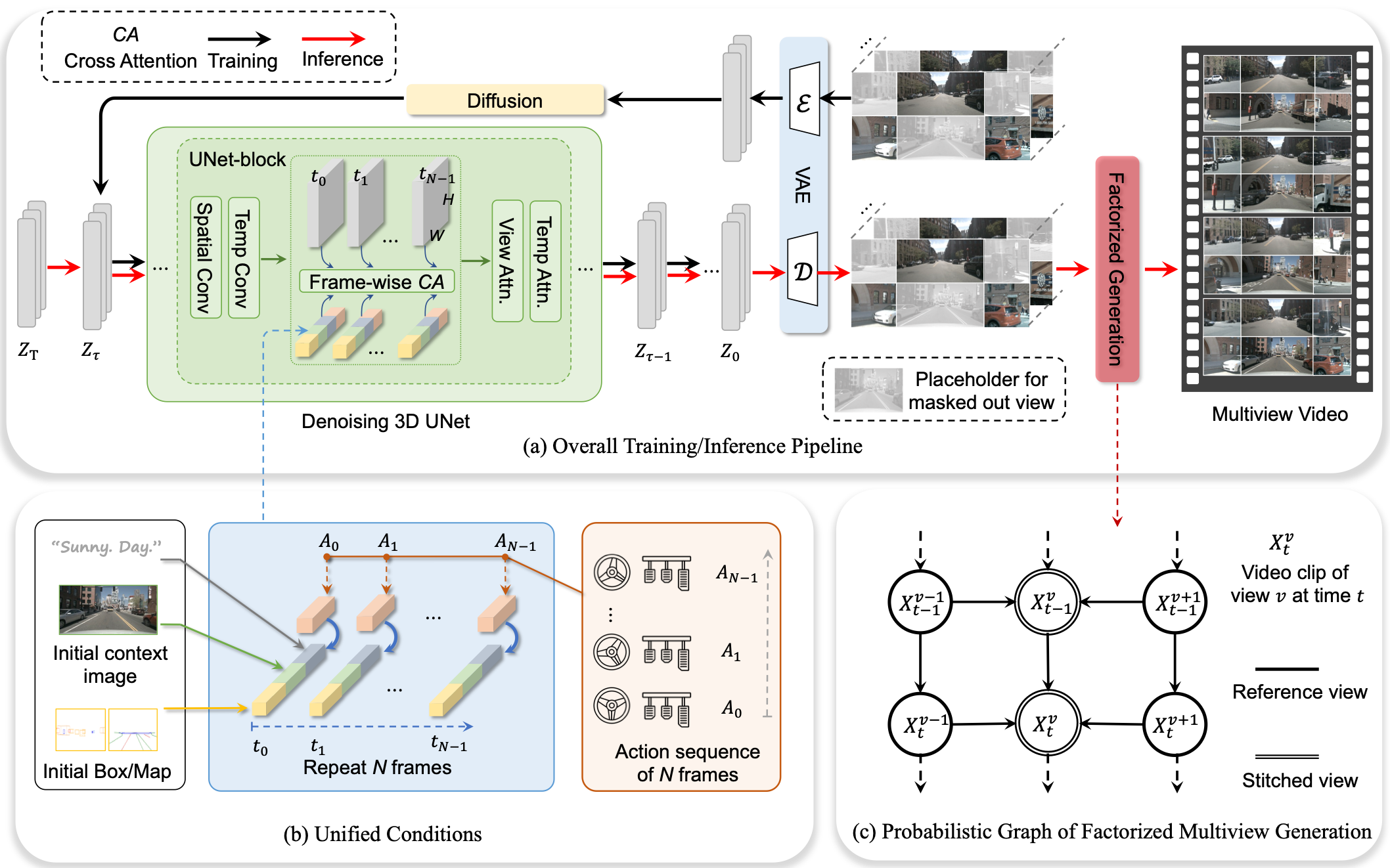
To this end, we propose Drive-WM, the first driving world model compatible with existing end-to-end planning models.
Through a joint spatial-temporal modeling facilitated by view factorization, our model is the first to generate high-fidelity multiview videos in driving scenes.
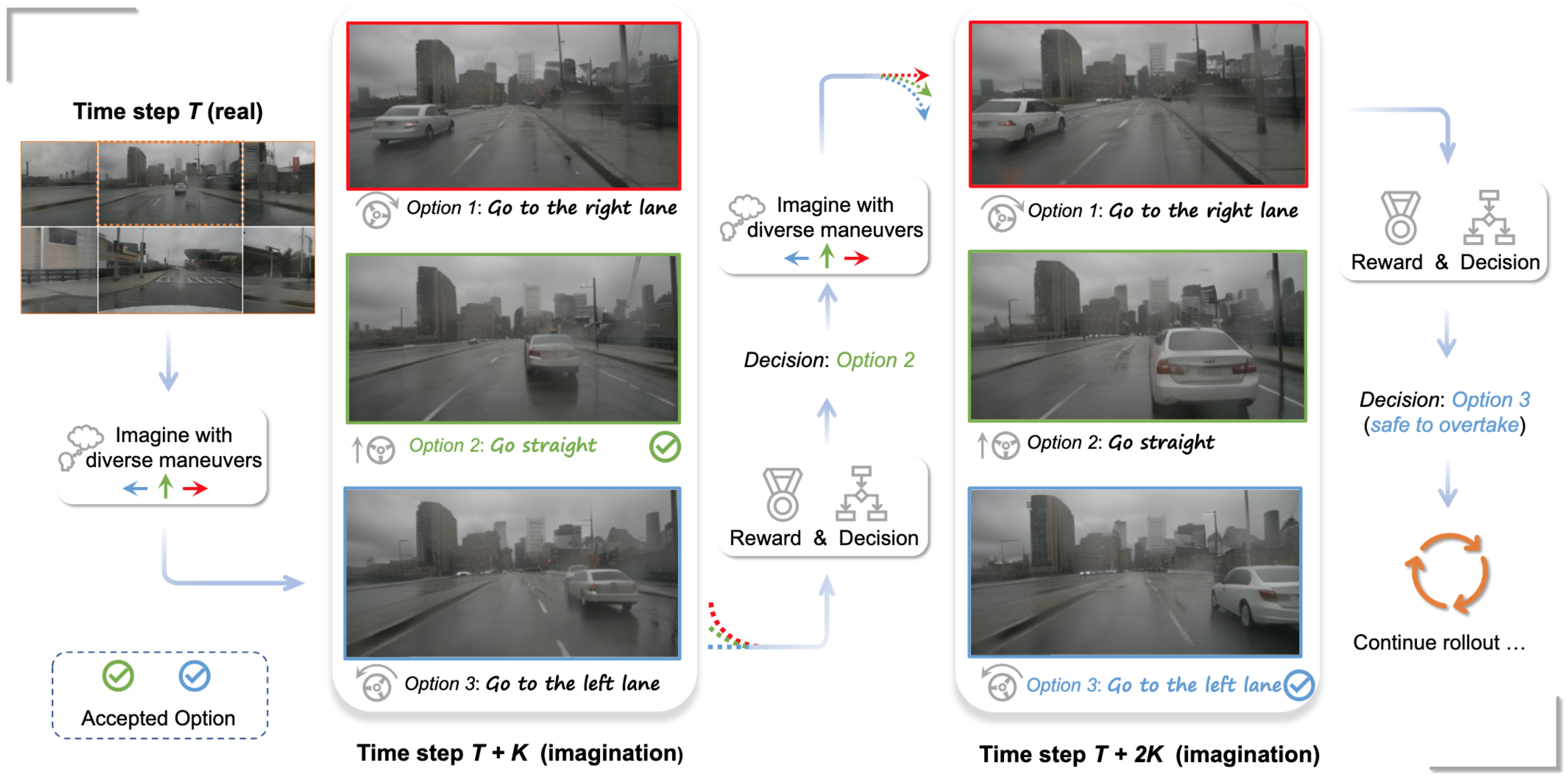
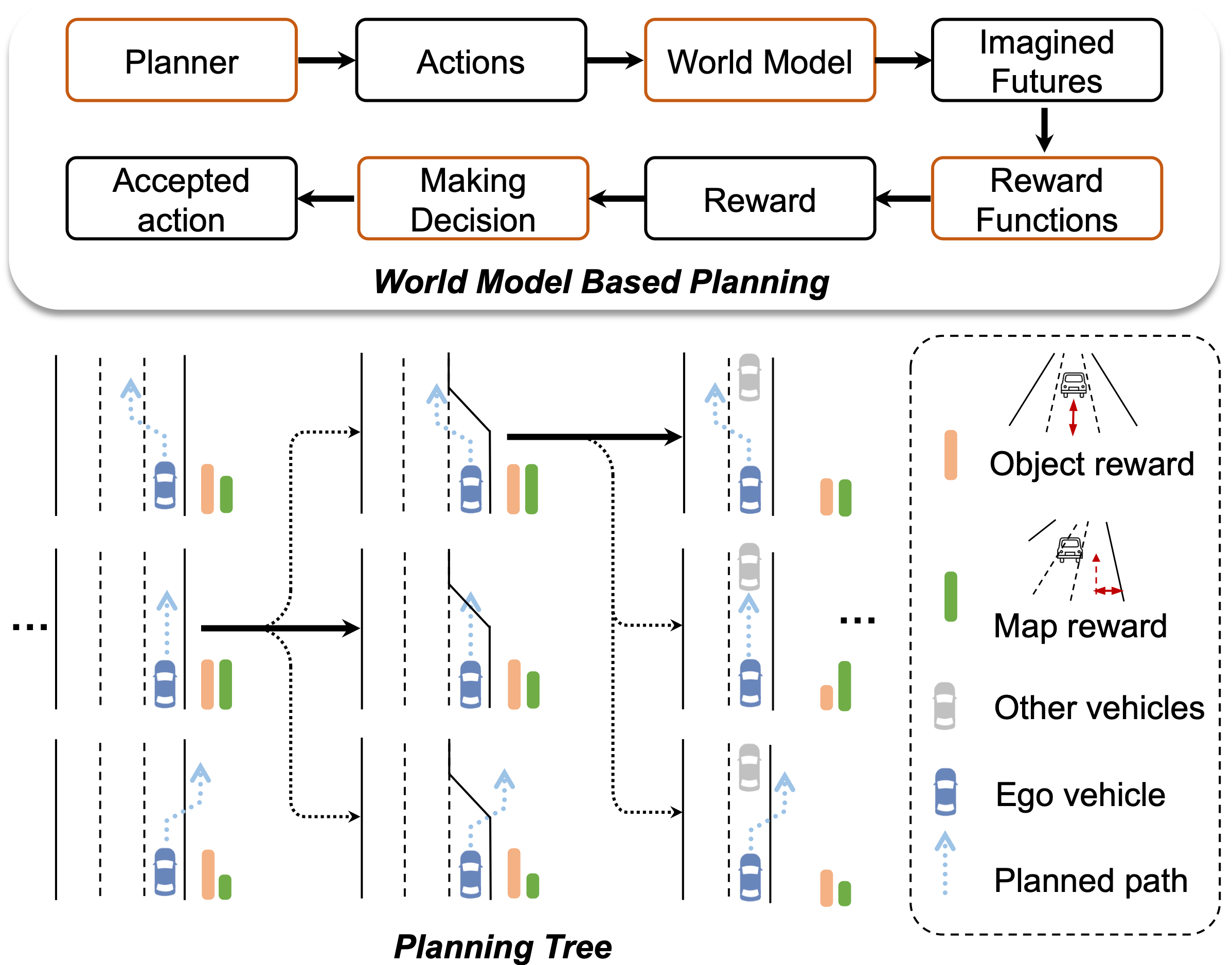
Building on its powerful generation ability, we showcase the potential of applying the world model for safe driving planning for the first time.
Particularly, our Drive-WM enables driving into multiple futures based on distinct driving maneuvers, and determines the optimal trajectory according to the image-based rewards.
Evaluation on real-world driving datasets verifies that our method could generate high-quality, consistent, and controllable multiview videos, opening up possibilities for real-world simulations and safe planning.